
As you may have noticed (those of you who still visit here), I haven’t posted anything substantive here in several months. Lots of reasons both personal and professional.
But let’s not dwell on the past. Let me tell you what I’m up to now.
At the first of this year, I started as the lead of a newly-forming test automation group at Polycom, working on the HDX video conferencing appliances. Although I’m not directly involved in the agile process here at Polycom, our new automation team is playing a crucial role in allowing the development organization to act in a more agile fashion.
Our product line is based on a codebase that has been around for a number of years, and since we develop entire appliances, it’s a pretty complex development environment with traditional applications, OS development, drivers, video and audio codecs, interoperability with other devices (both ours and other manufacturers’), etc.
Each software change goes through three levels of ‘promotions’, as we call it around here. First, it’s checked into the agile team’s codebase. Then, the team’s codebase is periodically promoted to the ‘integration’ code stream, and finally that codebase gets merged periodically into the global codebase.
Currently, promotions to the highest levels take place infrequently, these promotions are a significant event, and a lot of manual testing has to be done to ensure that the code to be promoted hasn’t broken anything.
This process has several problems. First, as alluded to above, a tremendous amount of time is devoted to manual regression testing. Second, regression issues are frequently not identified at the team level, and there are frequent high severity bug crises during promotions testing or, if a bug escapes through that, after the promotion takes place. And finally, since promotions are not daily, teams do not pull down the latest shared code frequently. So, a team develops against stale shared code for up to weeks at a time, and when they are ready to promote their code, a lot has changed in the shared codebase, leading to significant code merge problems.
The solution to this problems is obvious to agilists: continuous integration and automated testing. And in fact, that’s the initiative my group is involved in. Our goal is to have daily builds at all codebase levels and to run a suite of automated tests on each build. Considering the size and complexity of our environment, it’s an ambitious project, but I’ll keep you posted on the progress.
Author: Stan
Documenting code changes with defect reports
Today, Rafe Colburn listed four reasons to file the bugs found in code reviews. A commenter points out that defect reports aren’t the only way of communicating about changes to the code:
I guess it depends on the local culture, but in my experience, developers only look at a bug report if it’s assigned to them. The revision control system is a better way to see what’s happened recently.
In my ideal system, I would take things a little further: every commit must have one or more work items (requirements, defect reports) associated with it and an indication of whether each is in progress or completed. The argument for this is pretty simple: if you’re not implementing a requirement or fixing a bug, then why the heck are you changing code?
Additionally, the build system should display the commits in the build, the work items associated with each commit as well as a list of the changed files and an easy way to view file diffs for changes in each commit.
As a QA engineer, my need to see completed work items is obvious. However, the list of changed files and diffs provide a different type of equally useful data. This information provides me an easy way to familiarize myself with the code, input in deciding how to test the change, and opportunities for starting discussions with the programmers about their code.
When I describe this system to programmers, their first thought is often that it requires a lot of red tape/documentation. I have only worked with a system like this once in my career, and in that situation, the programmers did not find it onerous. It’s true that the programmers had to file defect reports for bugs that they fixed and found, but we relaxed our defect report standards in such cases; they didn’t have to fill out severity, steps to reproduce, etc., which allowed the developers to spend a very short amount of time filing the reports. We decided that having a minimal ‘placeholder’ defect report was good enough in many such cases if it allowed buy-in from the developers. Besides, as mentioned above, the reporting in the build system was a backup source of information about code changes.
Works on my machine
My favorite MeFi comment about this video: In my mind, the development work is done in the United States, and the QA testing is done in India, and QA keeps filing bugs that the face tracking software doesn’t work, and development engineers keep closing the bugs unfixed with the resolution “WORKS FOR ME”.
Algorithms Gone Wild
As noted by Consumerist, the screen shot below is from a search on Overstock.com for the term ‘Disney princess.” Note the ‘People who searched for…” box on the right:
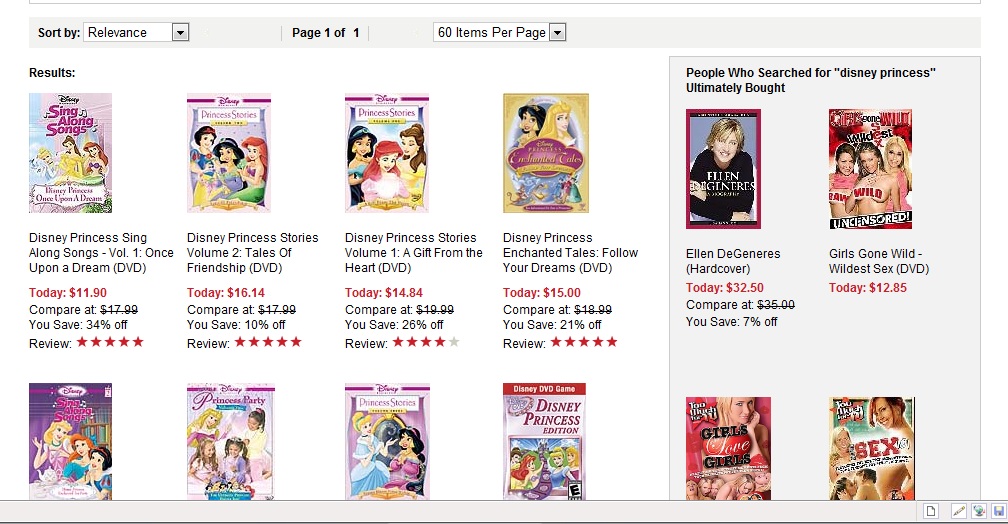
Oops.
This is depressing
The Incompetence of American Airlines and the Fate of Mr. X
In short:
- Graphic designer has poor experience with American Airlines’ web site
- Said designer mocks up a better page design for AA.com and blogs about it
- UX designer at American Airlines (who is clearly passionate about his work there) emails said designer, offering some insight into the challenges that they face with such a large team, a large web site/appliation, etc. Not all of the info is very flattering about AA, but, in my opinion at least, very typical of such companies and sites
- AA fires the UX designer.
From the graphic designer who started this whole thing:
When I first learned about [the firing], I was horrified. Mr. X is actually a good UX designer, and his email had me thinking there was hope for American Airlines. The guy clearly cared about his work and about the user experience at the company as a whole. But AA fired Mr. X because he cared. They fired him because he cared enough to reach out to a dissatisfied customer and help clear the company’s name in the best way he could.
UPDATE: I posted this to MetaFilter and got a lot of interesting comments.
Reinventing the wheel?
When I was job hunting earlier this year, I applied for an opening at S3 Technologies. At the time, I was puzzled by the emphasis on the military background of some of the company’s founders.
Today, I happened to visit S3’s web site and I was struck by something else. They seem to have invented a new methodology for software development:
Introducing Fight Club
Fight Club is an important step in what we’ve termed SPS, or the S3 Production System.
SPS is a uniquely efficient method of software delivery that solves your specific problem. Fight Club refers to four experts in software development and business working together in a room, removed from all distractions, and having every resource they need to quickly build and deliver the perfect solution. We realize that every company that makes a product, whether it is an automobile, a refrigerator, or a software product, can be more functional and efficient in development and assembly. S3’s scientists and analysts studied the best practices of global giants like Toyota and also looked at small but smart and growing technology businesses. In conducting our studies, we focused on best practices and time-tested methodologies and how they might be applied to the development of our solutions. We even improved a few of these processes along the way.
The result is SPS. We have refined the normal software model of design, build, test, and deploy in a manner that facilitates time to launch and quality of the product delivered. We believe in the “go and see” approach of Toyota, which means we sit down with your workers to see precisely how they’re doing the job that we’re going to automate. An intense verification and profile of your data beforehand will further tell us both what can and cannot be done.
And we’ve discovered there is often a difference between what a business thinks it “wants” and what it actually “needs.” That’s why we intensify the verification process and bring in quality assurance experts long before a solution is ready for development. We acquire a true understanding of what our customer needs and then we design and deliver the best product on the market faster than anyone else in the software business. And yes, we know that is a bold statement. But we’re only saying it because it’s true.
Wow. Why didn’t anyone else ever think to study Toyota’s manufacturing practices and apply it to software development? Furthermore, what an innovation: nobody has previously had the insight to put “experts in software development and business working together in a room, removed from all distractions, and having every resource they need” in order to “quickly build and deliver the perfect solution.”
Very odd.
“Oh, that’s easy. I can do it in a weekend”
In this blog post, The One in Which I Call Out Hacker News, Benjamin Pollack explains the reasoning behind a developer’s thinking that implementing something is simple, in this case, the claim that a developer could write the functionality behind Stack Overflow in a weekend.
When you put a developer in front of StackOverflow, they don’t really see StackOverflow. What they actually see is this:
create table QUESTION (ID identity primary key, TITLE varchar(255), BODY text, UPVOTES integer not null default 0, DOWNVOTES integer not null default 0, USER integer references USER(ID)); create table RESPONSE (ID identity primary key, BODY text, UPVOTES integer not null default 0, DOWNVOTES integer not null default 0, QUESTION integer references QUESTION(ID))If you then tell a developer to replicate StackOverflow, what goes into his head are the above two SQL tables and enough HTML to display them without formatting, and that really is completely doable in a weekend.
Benjamin acknowledges that that is indeed the core functionality behind the site, but then he lists all the other things that comprise the site–administration functionality, user functionality, look and feel, usability, etc. Furthermore, he points out what makes Stack Overflow successful is not really the core functionality, but all these other things. And implementing them successfully would take a lot of time–orders of magnitude longer than a weekend.
I would argue that it is often this thinking that often leads to software delays and poor quality. All the details that have to be covered are not taken into account when planning. The good news is that agile’s focus on breaking work into small units can help to counter this type of thinking. In the process of delineating all the tasks associated with a user story, the team should identify all of the details that are required for completion of the user story in the application.
QA’s dirty little secret
In my experience, one valuable skill that I’ve brought to the software development process is one that nobody wants to talk about: the willingness and ability to do tedious tasks that nobody else wants to do. Manual testing is the first such task that comes to people’s minds, but another example is going through the defect system on a regular basis to ensure that all defects have the proper data.
The good news is that agile has lowered the value of this skill. For one, making sure that processes, such as defect tracking, are followed is a team responsibility. Therefore, team members are more likely to do the right thing without being audited and the pain of bookkeeping lapses is felt more by the entire team.
More importantly, however, with agile there are simply fewer repetitive, tedious tasks. There is no process-for-process’ sake, so processes such as defect tracking workflows are reduced to the absolute minimum to make them work, and if they aren’t serving their intended purpose, they are adjusted based on feedback from the sprint retrospective. And since the pain of repetitive tasks are felt more by the whole team, there’s a greater emphasis on removing or automating as many such tasks as possible.
A note on defect severity and priority
In my previous post, Defect severity vs. priority, I used examples that explained the rationale behind deciding when to fix and not fix defects. Given agile’s focus on not allowing defects to go unaddressed, I now see that some people could have been confused by these examples.
Please note that that post addressed a general quality assurance concept, that the examples were hypothetical, and that it was not agile-specific.
I should write some more blog posts on my experiences with defects in agile environments.
Defect severity vs. priority
In my recent post, Unnecessary abstraction, I used defect severity as an example. I also mentioned that more a more descriptive (less abstract) name for this information would be something like “Customer severity” or “Impact on user.”
In my post, I assumed a specific definition of severity. In my career, I’ve dealt repeatedly with confusion between defect severity and defect priority, so I thought I should document my preferred definitions here.
I define defect severity, as I mentioned above, as the effect on the software user. If severity is a dropdown field in the defect management software, I usually recommend values such as
- Critical functionality broken, no workaround
- Non-critical functionality broken, or critical with workaround
- Minor functional defect
- Cosmetic or minor usability issue
As I mentioned in my earlier post, the values for this field don’t have to be hierarchical. Who’s to say that ‘Non-critical functionality is broken’ is more or less severe than ‘Critical functionality broken, but with workaround’?
Unless new information is discovered regarding a defect (e.g., a work-around is identified), severity should not change.
When putting together a defect tracking process, I suggest that the person who enters the defect be required to provide a severity.
Defect priority represents the development team’s priority in regard to addressing the defect. It is a risk-management decision based on technical and business considerations related to addressing the defect. To make the term less abstract, I usually propose it be called ‘Development priority’ or something similar.
Priority can be determined only after technical and business considerations related to fixing the defect are identified; therefore the best time to assess priority is after a short examination of the defect, typically during a ‘bug scrub’ attended by both the product owner and technical representatives.
Here are some examples I give when explaining severity and priority:
High severity, low priority – Critical impact on user: nuclear missiles are launched by accident. Factor influencing priority: analysis reveals that this defect can only be encountered on the second Tuesday of the first month of the twentieth year of each millennium, and only then if it’s raining and five other failsafes have failed.
Business decision: the likelihood of the user encountering this defect is so low that we don’t feel it’s necessary to fix it. We can mitigate the situation directly with the user.
High severity, low priority – Critical impact on user: when this error is encountered, the application must be killed and restarted, which can take the application off-line for several minutes. Factors influencing priority: (1) analysis reveals that it will take our dev team six months full-time refactoring work fix this defect. We’d have to put all other work on hold for that time. (2) Since this is a mission-critical enterprise application, we tell customers to deploy it in a redundant environment that can handle a server going down, planned or unplanned.
Business decision: it’s a better business investment to make customers aware of the issue, how often they’re likely to encounter it, and how to work through an incidence of it than to devote the time to fixing it.
Low severity, high priority – Minimal user impact: typo. Factors influencing priority. (1) The typo appears prominently on our login screen; it’s not a terribly big deal for existing customers, but it’s the first thing our sales engineers demo to prospective customers, and (2) the effort to fix the typo is minimal.
Decision: fix it for next release and release it as an unofficial hotfix for our field personnel.